 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlucoFM: A Dual-Stream Foundation Model for Continuous Glucose Monitoring
May 29, 2026Continuous glucose monitoring (CGM) provides a dense view of daily metabolic physiology, yet existing generic time-series and CGM-specific foundation models often encode glucose traces as entangled single-stream sequences, leaving the distinct temporal structure of glycemic dynamics only implicitly modeled. We present GlucoFM, a lightweight CGM foundation model that aligns irregular recordings to a 24-hour chronological grid, preserves observation masks, and decomposes glucose dynamics into slow physiological state and transient event streams, capturing low-frequency glycemic baselines and short-term deviations that may reflect acute physiological responses or sensor artifacts. GlucoFM is pretrained on 109,066 hours of unlabeled CGM recordings from 477 subjects with two complementary objectives: masked contextual latent prediction over fused daily representations and temporal dynamics prediction over state and event streams. Across four diverse cohorts and seven clinical prediction tasks, GlucoFM achieves the strongest subject-disjoint linear-probing performance among evaluated baselines, improving average PR-AUC by 4.1 points over the best CGM-specific foundation model. Its gains are most pronounced on core metabolic outcomes, leading PR-AUC on all diabetes-risk and $β$-cell dysfunction tasks and on 3 of 4 insulin-resistance tasks. GlucoFM also achieves the best overall cross-dataset transfer performance and strong few-shot adaptation among evaluated methods, and consistent gains when aggregating multiple days for subject-level prediction, highlighting physiology-aware decomposition as an effective inductive bias for transferable CGM representation learning.
Towards a General Intelligence and Interface for Wearable Health Data
May 21, 2026While ubiquitous wearable sensors capture a wealth of behavioral and physiological information, effectively transforming these signals into personalized health insights is challenging. Specifically, converting low-level sensor data into representations capable of characterizing higher-level states is difficult due to high phenotypic diversity and variation in individual baseline health, physiology, and lifestyle factors. Moreover, collecting wearable data paired with health outcome annotations is laborious and expensive, and retrospective annotation remains practically unfeasible, contributing to a scarcity of data with high-quality labels. To overcome these limitations, we propose a foundation model for wearable health that is pretrained on more than one trillion minutes of unlabeled sensor signals drawn from a large cohort of five million participants. We demonstrate that the joint scaling of model capacity and pretraining data volume leads to systematic improvements in performance, as evaluated on a diverse set of 35 health prediction tasks, spanning cardiovascular, metabolic, sleep, and mental health, as well as lifestyle choices and demographic factors. We find that this population scale representation unlocks label-efficient few-shot learning and generative capabilities for robust daily metric estimation. To further leverage this learned representation, we deploy a classroom of LLM agents to autonomously search the space of downstream predictive heads built on the model embeddings, showing broad performance improvements that increase with LLM model capacity. Finally, we show how integrating these downstream predictors into a Personal Health Agent can support model responses that are more relevant, contextually aware, and safe, and we validate this via 1,860 ratings from a cohort of clinicians.
SymptomAI: Towards a Conversational AI Agent for Everyday Symptom Assessment
May 05, 2026Language models excel at diagnostic assessments on currated medical case-studies and vignettes, performing on par with, or better than, clinical professionals. However, existing studies focus on complex scenarios with rich context making it difficult to draw conclusions about how these systems perform for patients reporting symptoms in everyday life. We deployed SymptomAI, a set of conversational AI agents for end-to-end patient interviewing and differential diagnosis (DDx), via the Fitbit app in a study that randomized participants (N=13,917) to interact with five AI agents. This corpus captures diverse communication and a realistic distribution of illnesses from a real world population. A subset of 1,228 participants reported a clinician-provided diagnosis, and 517 of these were further evaluated by a panel of clinicians during over 250 hours of annotation. SymptomAI DDx were significantly more accurate (OR = 2.47, p < 0.001) than those from independent clinicians given the same dialogue in a blinded randomized comparison. Moreover, agentic strategies which conduct a dedicated symptom interview that elicit additional symptom information before providing a diagnosis, perform substantially better than baseline, user-guided conversations (p < 0.001). An auxiliary analysis on 1,509 conversations from a general US population panel validated that these results generalize beyond wearable device users. We used SymptomAI diagnoses as labels for all 13,917 participants to analyze over 500,000 days of wearable metrics across nearly 400 unique conditions. We identified strong associations between acute infections and physiological shifts (e.g., OR > 7 for influenza). While limited by self-reported ground truth, these results demonstrate the benefits of a dedicated and complete symptom interview compared to a user-guided symptom discussion, which is the default of most consumer LLMs.
CoDaS: AI Co-Data-Scientist for Biomarker Discovery via Wearable Sensors
Apr 16, 2026Scientific discovery in digital health requires converting continuous physiological signals from wearable devices into clinically actionable biomarkers. We introduce CoDaS (AI Co-Data-Scientist), a multi-agent system that structures biomarker discovery as an iterative process combining hypothesis generation, statistical analysis, adversarial validation, and literature-grounded reasoning with human oversight using large-scale wearable datasets. Across three cohorts totaling 9,279 participant-observations, CoDaS identified 41 candidate digital biomarkers for mental health and 25 for metabolic outcomes, each subjected to an internal validation battery spanning replication, stability, robustness, and discriminative power. Across two independent depression cohorts, CoDaS surfaced circadian instability-related features in both datasets, reflected in sleep duration variability (DWB, ρ= 0.252, p < 0.001) and sleep onset variability (GLOBEM, ρ= 0.126, p < 0.001). In a metabolic cohort, CoDaS derived a cardiovascular fitness index (steps/resting heart rate; ρ= -0.374, p < 0.001), and recovered established clinical associations, including the hepatic function ratio (AST/ALT; ρ= -0.375, p < 0.001), a known correlate of insulin resistance. Incorporating CoDaS-derived features alongside demographic variables led to modest but consistent improvements in predictive performance, with cross-validated ΔR^2 increases of 0.040 for depression and 0.021 for insulin resistance. These findings suggest that CoDaS enables systematic and traceable hypothesis generation and prioritization for biomarker discovery from large-scale wearable data.
How Well Do Multimodal Models Reason on ECG Signals?
Feb 27, 2026While multimodal large language models offer a promising solution to the "black box" nature of health AI by generating interpretable reasoning traces, verifying the validity of these traces remains a critical challenge. Existing evaluation methods are either unscalable, relying on manual clinician review, or superficial, utilizing proxy metrics (e.g. QA) that fail to capture the semantic correctness of clinical logic. In this work, we introduce a reproducible framework for evaluating reasoning in ECG signals. We propose decomposing reasoning into two distinct, components: (i) Perception, the accurate identification of patterns within the raw signal, and (ii) Deduction, the logical application of domain knowledge to those patterns. To evaluate Perception, we employ an agentic framework that generates code to empirically verify the temporal structures described in the reasoning trace. To evaluate Deduction, we measure the alignment of the model's logic against a structured database of established clinical criteria in a retrieval-based approach. This dual-verification method enables the scalable assessment of "true" reasoning capabilities.
TS-Haystack: A Multi-Scale Retrieval Benchmark for Time Series Language Models
Feb 15, 2026Time Series Language Models (TSLMs) are emerging as unified models for reasoning over continuous signals in natural language. However, long-context retrieval remains a major limitation: existing models are typically trained and evaluated on short sequences, while real-world time-series sensor streams can span millions of datapoints. This mismatch requires precise temporal localization under strict computational constraints, a regime that is not captured by current benchmarks. We introduce TS-Haystack, a long-context temporal retrieval benchmark comprising ten task types across four categories: direct retrieval, temporal reasoning, multi-step reasoning and contextual anomaly. The benchmark uses controlled needle insertion by embedding short activity bouts into longer longitudinal accelerometer recordings, enabling systematic evaluation across context lengths ranging from seconds to 2 hours per sample. We hypothesize that existing TSLM time series encoders overlook temporal granularity as context length increases, creating a task-dependent effect: compression aids classification but impairs retrieval of localized events. Across multiple model and encoding strategies, we observe a consistent divergence between classification and retrieval behavior. Learned latent compression preserves or improves classification accuracy at compression ratios up to 176$\times$, but retrieval performance degrades with context length, incurring in the loss of temporally localized information. These results highlight the importance of architectural designs that decouple sequence length from computational complexity while preserving temporal fidelity.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025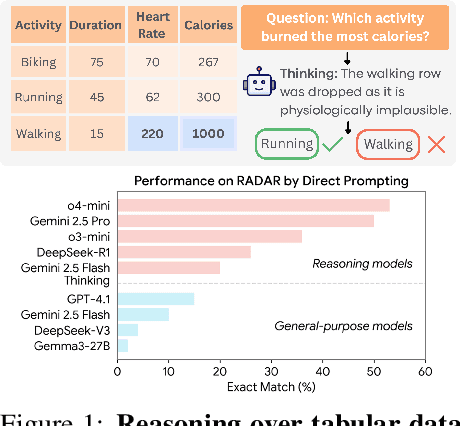
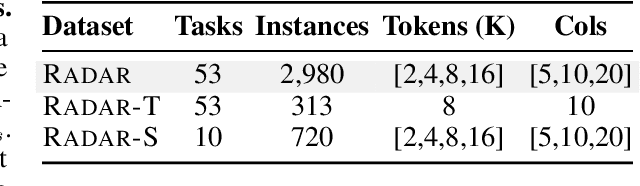
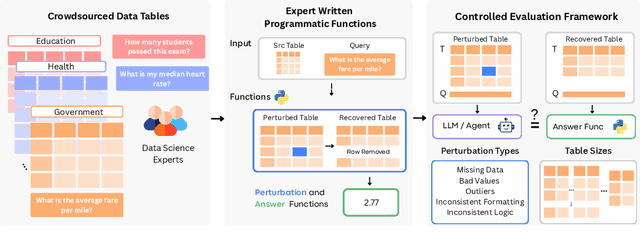
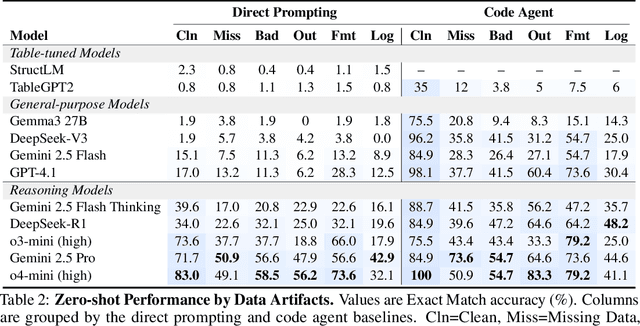
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025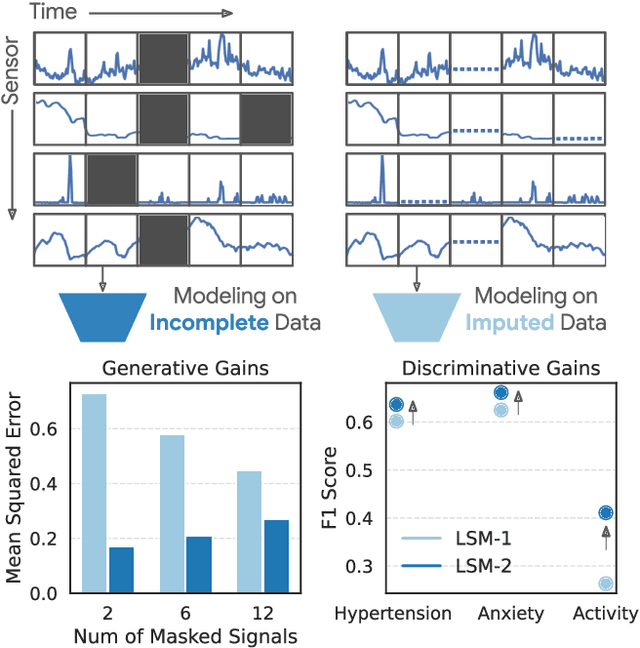
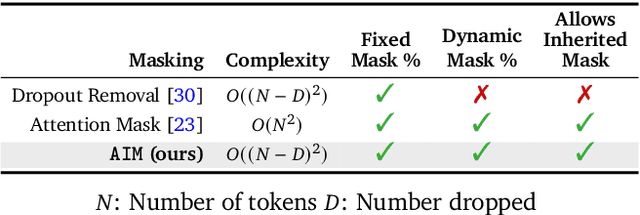
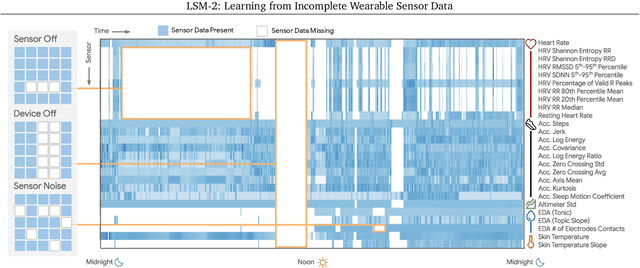
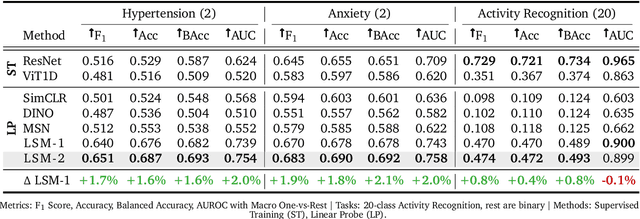
Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Pulse-PPG: An Open-Source Field-Trained PPG Foundation Model for Wearable Applications Across Lab and Field Settings
Feb 03, 2025Photoplethysmography (PPG)-based foundation models are gaining traction due to the widespread use of PPG in biosignal monitoring and their potential to generalize across diverse health applications. In this paper, we introduce Pulse-PPG, the first open-source PPG foundation model trained exclusively on raw PPG data collected over a 100-day field study with 120 participants. Existing PPG foundation models are either open-source but trained on clinical data or closed-source, limiting their applicability in real-world settings. We evaluate Pulse-PPG across multiple datasets and downstream tasks, comparing its performance against a state-of-the-art foundation model trained on clinical data. Our results demonstrate that Pulse-PPG, trained on uncurated field data, exhibits superior generalization across clinical and mobile health applications in both lab and field settings. This suggests that exposure to real-world variability enables the model to learn fine-grained representations, making it more adaptable across tasks. Furthermore, pre-training on field data surprisingly outperforms its pre-training on clinical data in many tasks, reinforcing the importance of training on real-world, diverse datasets. To encourage further advancements in robust foundation models leveraging field data, we plan to release Pulse-PPG, providing researchers with a powerful resource for developing more generalizable PPG-based models.